
券商中國
王蕊
2025-01-01 07:54


國產大模型DeepSeek在全球火了,并帶火了一個95后AI“天才少女”羅福莉。
最近,中國頭部量化私募公司幻方量化旗下專注于AI大模型研究開發的Deepseek(深度求索公司),宣布旗下的全新系列模型DeepSeek-V3首個版本上線并同步開源。DeepSeek-V3是深度求索自研的MoE模型(混合專家大模型),不僅以卓越的性能超越或媲美全球頂級的開源及閉源模型,更重要的是訓練成本極低,被稱為“AI界的拼多多”,以史無前例的性價比被國內外一眾圈內大佬點贊,引發廣泛關注。
與DeepSeek一起進入大家視野的,是95后AI“天才少女”羅福莉。她曾在DeepSeek參與了DeepSeek-V2的研發,是這款模型的關鍵開發者之一。在DeepSeek-V3發布前幾天,媒體報道稱小米創始人雷軍已開出千萬年薪,將羅福莉招至麾下,羅福莉將就職于小米AI實驗室,領導大模型團隊。
“AI界拼多多”刷屏海外
據最新發布的技術報告,DeepSeek-V3參數量為671B,激活參數為37B,使用的預訓練token量為14.8萬億。其多項評測成績超越了阿里的Qwen2.5-72B和MetadeLlama-3.1-405B等其他開源模型,并在性能上和世界頂尖的閉源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。

“中國AI公司Deepseek發布并開源了一個前沿的大語言模型,而其訓練的預算卻非常低。”前OpenAI聯創、知名AI科學家AndrejKarpathy在其個人社交平臺上表示,DeepSeek-V3整個訓練過程僅用了不到280萬GPU小時,相比之下,Meta旗下頂尖的開源模型Llama-3405B的訓練時長是3080萬GPU小時。如果DeepSeekV3的優良表現能夠得到廣泛驗證,那么這將是資源有限情況下對研究和工程的一次出色展示。
若從成本上進行更直觀的對比,假設H800的租金為每GPU小時2美元,DeepSeek-V3的總訓練成本僅為600萬美元不到,是Llama-3405B超6000萬美元訓練成本的十分之一不到。
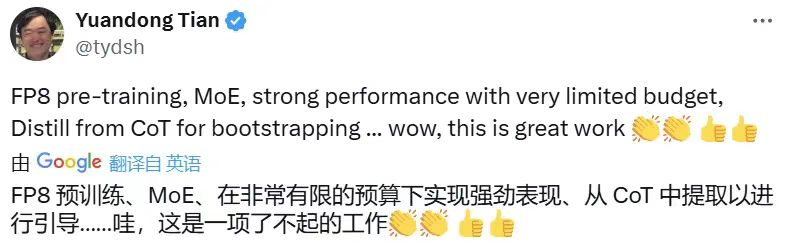
極高的性價比讓DeepSeek-V3一經發布便引發國內外廣泛關注。Meta的AI研究科學家田淵棟稱“在非常有限的預算下實現強勁表現”,“這是一項了不起的工作”。知名AI數據公司ScaleAI創始人兼CEOAlexandrWang也表示,DeepSeek-V3“訓練所需計算量減少了10倍”,“在美國休息的時候,他們努力工作,以更低的成本、更快的速度和更強的實力迎頭趕上。”
這一圈粉無數的大模型,由被稱為“AI界拼多多”的DeepSeek研發。公開資料顯示,DeepSeek專注于開發先進的大語言模型和相關技術,由國內知名量化資管巨頭幻方量化于2023年創立,也被美國硅谷譽為“來自東方的神秘力量”。
事實上,DeepSeek并非第一次“出圈”。早在半年前,其發布的DeepSeek-V2就因性能達GPT-4級別,但開源、可免費商用、且API價格僅為GPT-4-Turbo的百分之一而引發業內關注。對于為何能做到如此高的性價比,DeepSeek官方解釋稱,DeepSeek-V2采用了創新的架構,例如注意力機制方面的MLA(多頭潛在注意力)和前饋網絡方面的DeepSeekMoE架構等,以實現具有更高經濟性的訓練效果和更高效的推理。
正因為在訓練效率和成本方面的優勢,DeepSeek也是國內最早開啟大模型降價的廠商,也是大模型價格戰的源頭和推動者。在其發布DeepSeek-V2之后,字節、阿里、百度等廠商紛紛跟進降價。同時,DeepSeek也是中國互聯網大廠以外,唯一一家儲備了萬張A100芯片的公司,這為其早期的技術研發提供了堅實的算力基礎。
“我們不是有意成為一條鯰魚,只是不小心成了一條鯰魚。”在回應當初為何打響大模型價格戰第一槍時,DeepSeek創始人梁文鋒表示。這位畢業于浙江大學電子工程系的80后,一直潛心研究技術。據媒體報道,梁文鋒在工作中始終保持著低調的作風,和所有研究員一樣,每天“看論文,寫代碼,參與小組討論”。
一名人工智能行業資深業內人士向證券時報記者分析稱,DeepSeek以200人左右的小團隊,且不依靠外部融資,做出了一個有性價比并被全球主流AI界人士所認可的大模型。“一是他們在早期就買了很多算力卡,投入了很多資源做研究;二是他們是做量化的,不像大廠有其他各種各樣的盈利需求,也跟他們不構成競爭關系,能更專注于模型開發。”該業內人士表示。
背后的AI“天才少女”引發關注
在DeepSeek-V3爆火之后,背后的AI“天才少女”羅福莉也進入了人們的視野。據媒體報道,小米創始人雷軍以千萬年薪招攬DeepSeek開源大模型DeepSeek-V2的關鍵開發者之一羅福莉,領導小米AI大模型團隊。

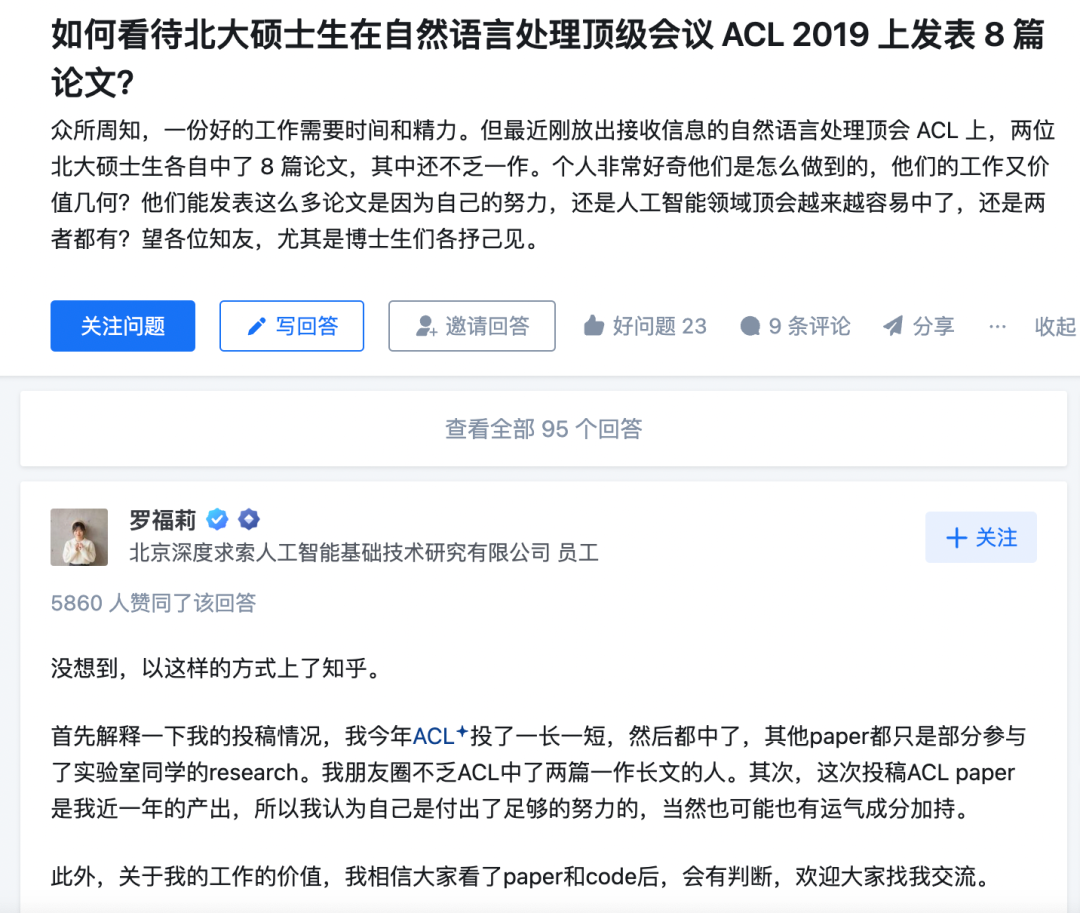
公開資料顯示,羅福莉本科就讀于北京師范大學計算機專業,碩士畢業于北京大學計算語言學專業。2019年,還在北大讀碩士的她在人工智能領域頂級國際會議ACL上發表8篇論文(其中2篇一作),登上了知乎熱搜。羅福莉用本人知乎賬號回應稱,“這次投稿ACL是我近一年的產出,所以我認為自己是付出了足夠的努力的,當然也可能也有運氣成分加持。”
碩士畢業后,羅福莉先是進入阿里達摩院做人工智能研究,從事預訓練語言模型相關的工作,負責阿里達摩院AliceMind開源項目,主導開發了多語言預訓練模型VECO。2022年,羅福莉加入幻方量化從事深度學習相關策略建模和算法研究,后又跳槽到DeepSeek擔任深度學習研究員,參與研發MoE大模型DeepSeek-V2。
今年5月,在DeepSeek-V2發布以后,羅福莉在知乎上撰文,發表了對于DeepSeek-V2的看法。她表示,“單論DeepSeek-V2模型的中文水平,是真實處在國內外閉源模型的第一梯隊”,“外加1元/百萬輸入Tokens的價格,只有GPT4價格的1/100,性價比之王”。
事實上,羅福莉被重金招入小米,是小米全面發力AI大模型的其中一個動作。2023年4月,小米正式組建了AI實驗室大模型團隊,并表示將不斷挖掘AI相關的用戶場景,發揮自身技術優勢,并以開放的態度與合作伙伴開拓更多機會。今年11月,小米成立了專門的AI平臺部,小米的元老級技術大牛張鐸為負責人。張鐸本碩畢業于清華計算機系,曾被雷軍公開稱贊是“小米的大神”,送以“鐸神”的稱號。
兵馬未動,糧草先行。除了招募人才以外,最近,媒體報道稱小米正著手搭建自己的GPU萬卡集群,并在過去幾個月里持續提升算力儲備,為大模型研發提供更充分的算力供給。雷軍在公開演講時曾表示,小米做大模型的思路和很多公司不太一樣,選擇主力突破的是輕量化和本地部署。對于小米這樣無論在手機還是造車上都講究“性價比”的公司而言,如何在燒錢的大模型業務中平衡成本,無疑是雷軍考慮的核心問題。而這,或許也是擁有DeepSeek-V2研發背景的羅福莉被雷軍看中的原因。
責編:葉舒筠
校對:祝甜婷






